
After reading this post, you will know everything there is to know about crawl budget, have a hit list of tasks to start optimising your budget and be well on the way to improving your crawl rate. Let’s start with the burning question . . .
What is a crawl budget?
Your Crawl Budget is the exact number of times a search engine like Google or Bing crawls your website in a specific time period. For example, if Googlebot crawls your website 50 times a day, we can extrapolate this to give a monthly budget of roughly 1500. The best place to get started when determining your monthly crawl budget is to use Google Search Cfonsole and Bing Webmaster Tools.
Search engines use web crawler bots (known as spiders) to look at every single web page on the internet, collect information and then add them to their search engine index. In addition to deciphering the information on the page, the bots also look at a site’s internal and external links to help get a better understanding of the web pages.
The two most common bots are Googlebot and Bingbot.
Why do you need to optimise your crawl budget?
How often have you set up a website in webmaster tools, submitted it for crawling and then forgotten about it? This practice is very risky – you are essentially telling search engines to make sense of your pages while assuming that all pages will be treated equally and your best content will be indexed. In reality, you may see certain pages not getting indexed and crawlers may not reach your best content, or may limit visibility in search engine results for your target keywords.
Optimising your crawl budget allows you to take control of which pages search engines index, direct search engine bots to your most valuable pages, and make sure your budget stretches as far as possible.
How do you find your crawl budget?
Let’s use Google Search Console as an example. Head to Crawl > Crawl Stats to find your Pages crawled per day figure as highlighted in red below:
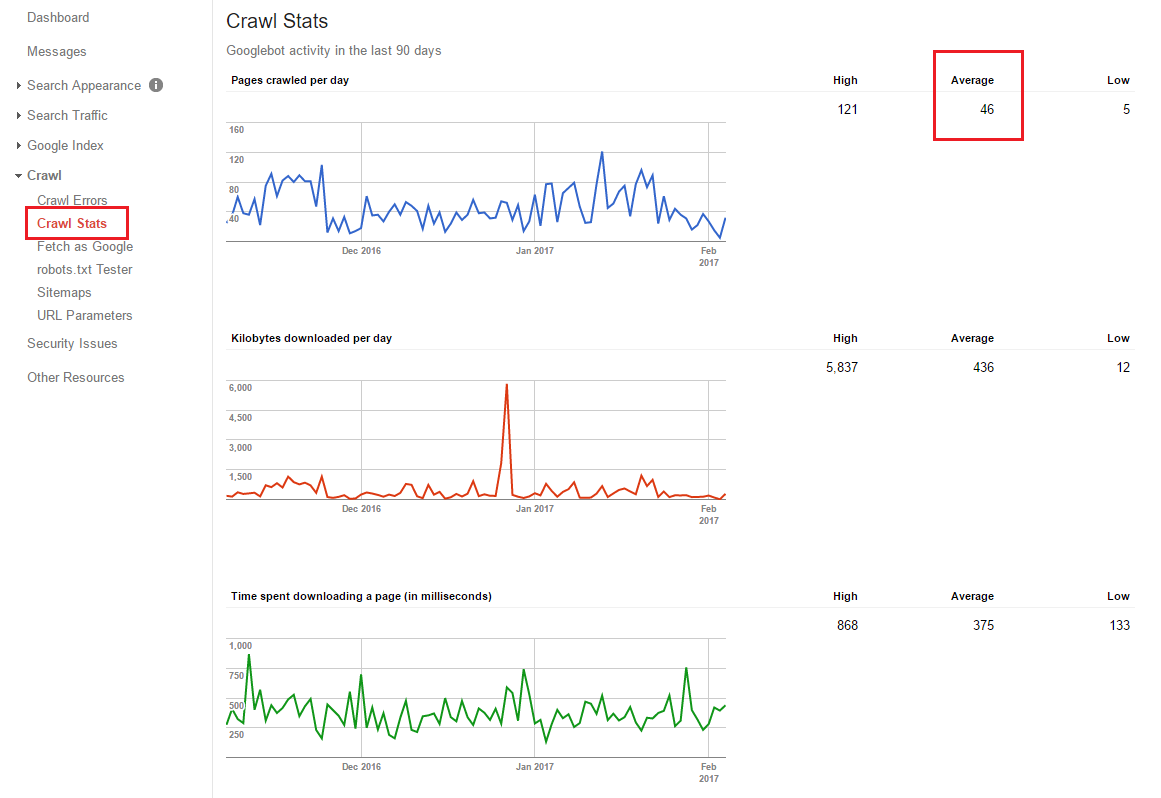
Once you have this figure, times it by 30 and you have your monthly crawl budget.
It is important to remember that optimising your crawl budget is not strictly the same as SEO. This practice is designed to make your pages more visible to search engines, which will ultimately impact your search engine rankings; however it is designed solely for bots – not humans.
So, now you know what your crawl budget is – let’s look at 15 ways we can optimise your budget to make your site as crawlable as possible for search engine spiders.
1. Set up Google Search Console & Bing Webmaster Tools
First of all, let’s look at how these two tools are defined:
Google Search Console – “A free service offered by Google that helps you monitor and maintain your site’s presence in Google Search results”
Bing Webmaster Tools – “A free service as part of Microsoft’s Bing search engine which allows webmasters to add their websites to the Bing index crawler”
As mentioned earlier, Google Search Console and Bing Webmaster Tools should be the starting point when determining your crawl budget. These tools allow you to see how many pages are crawled on your website each day, split between high, average and low, as follows:
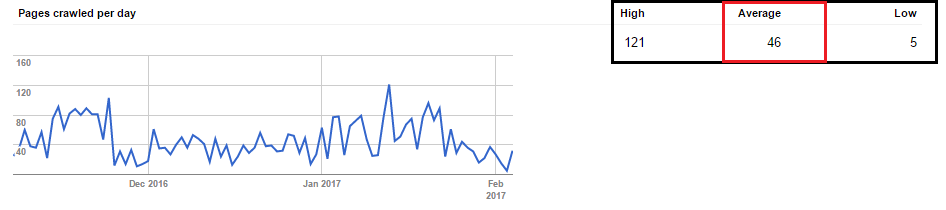
In order to have enough data, use your monthly crawl budget. In addition to crawl data, these tools give you access a number of technical reports, such as:
- Site Errors
- URL Parameters
- Index Status
- Blocked Resources
- Remove URLs
Get these set up and have a look around, there are some really useful resources in there – this Google Search Console guide is a great starting point.
2. Make sure your pages are crawlable
To ensure search engines have a trouble free time crawling your site, follow these steps:
- Be cautious when using Flash and AJAX (especially in your navigation)
Flash and AJAX are not by any means bad, however they do have an impact on the crawlability of your website. As a rule of thumb, avoid using both of these within your navigation – this will make it more complicated for search engines to crawl your site. - Avoid using Javascript in your navigation
In 2007, Google stated that “While we are working to better understand JavaScript, your best bet for creating a site that’s crawlable by Google and other search engines is to provide HTML links to your content.” As with Flash and AJAX, if you are using it, ensure it’s easy to crawl and is not used in your site’s navigation. - Use clear, non-dynamic URLs
Dynamic URLs (any URL with a non-alphabetical/numerical character in it) are in some cases a necessity, for example when managing a large ecommerce store it can become difficult to have a URL structure that does not contain question marks due to the database lookup. However, the length of this URL can be managed (in most cases) and has a direct effect on the crawlability of your web pages. Google said: “Not every search engine spider crawls dynamic pages as well as static pages. It helps to keep the parameters short and the number of them few.” If you have dynamic URLs, keep them as short as possible to help search engines crawl your web pages. - Ensure your sitemap is always up to date
An XML Sitemap is a list of your URLs that can be submitted to search engines for indexing but is by no means a subsitute for a good site navigation. This can be submitted through Google Search Console and Bing Webmaster Tools and is a great way to help guide bots through your website.
3. Utilise a Robots.txt file
Robots.txt is a simple text file that allows you to instruct search engine robots how to crawl your website. We have produced an excellent guide to robots.txt and Moz provides a great cheat sheet on robots.txt which covers in depth formatting and tags. Common setups include :
- Blocking access (Disallow: /)
- Blocking folders (Disallow: /folder/)
- Blocking files (Disallow: /file.html)
Certain parts of your website will not need indexing but will still be eligible to show up in search results – this is where a robots.txt file comes in to help inform search engines and assist the crawling process.
4. Reduce redirect chains
Every time you redirect a page, a little bit of your crawl budget is used up. Having a large number of 301/302 redirects in a sequence can cause Googlebot/Bingbot to drop off before they reach the page you want crawling. As a rule of thumb – keep redirects to a minimum and if you do use them, ensure there are no more than two in a redirect chain. Any more than this runs the risk of missing out on indexing!
5. Clean up your broken links
Now you have Google Search Console and Bing Webmaster Tools set up, you can access to your broken link report within search console. Head over to Crawl > Crawl Errors and you will see a report similar to this:
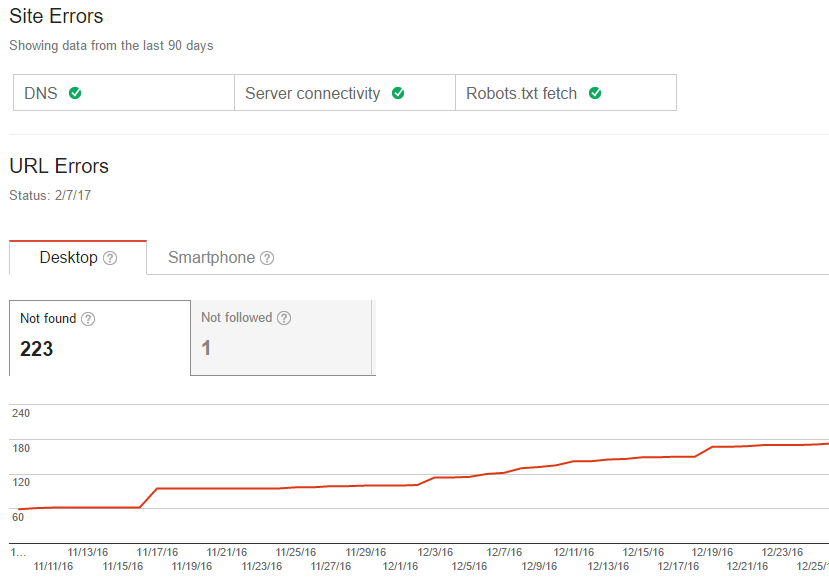
In Bing, head to Reports & Data > Crawl Information and you will see a report like this:

These reports will identify your broken links, whether they are 404, 301 or 302 – you will need to get these sorted to ensure search engine crawlers have a smooth ride while scanning through your website. As soon as a bot lands on your page and hits a broken link they will simply move onto the next one, meaning that the original page that contains the broken link will not be crawled.
6. Audit and update your sitemap
Google defines a Sitemap as “A file where you can list the web pages of your site to to tell Google and other search engines about the organisation of your site content. Search engine web crawlers like Googlebot read this file to more intelligently crawl your site.” Sitemaps also provide metadata associated with your pages such as when it was last updated, how often the page is changed and the importance of the page in the hierarchy of your site.
If you don’t currently have a sitemap, head over to Check Domains sitemap generator, stick your site URL in the header box and create a your sitemap. If you currently have a sitemap, head into the file and look for any unnecessary redirects, blocked pages, duplicate content etc. Once you’ve cleaned up your sitemap, head to Google Search Console and Bing Webmaster Tools where you can submit your file for verification. From here, upload this file to the root domain of your website e.g. www.mysite.com/sitemap.xml and you are good to go.
Depending on your CMS, you may be able to get a sitemap plug in such as Yoast that will auto-generate the sitemap as you add or remove pages. As a side note, sitemaps can also be incorporated into the website navigation to offer users a view of every page on your website, Zavvi use this well:
Having a sitemap will not greatly boost your rankings but will definitely help search engines understand your website.
7. Tell search engines how to handle parameters in your URLs
Google Search Console and Bing Webmaster Tools allow you to categorise certain parameters from your URLs to aid the crawling process. If you have UTM tagging set up, or are sending mail campaigns that link to your website, these links will typically have extra information appended to end of the URL – in most cases you will not want this page indexing as this will create duplicate content.
In light of this, search engines allow you to identify which parameters to index and which to ignore. Google Search Console is a great place to start with this. Head to Crawl > URL Parameters and you will see a report similar to this:
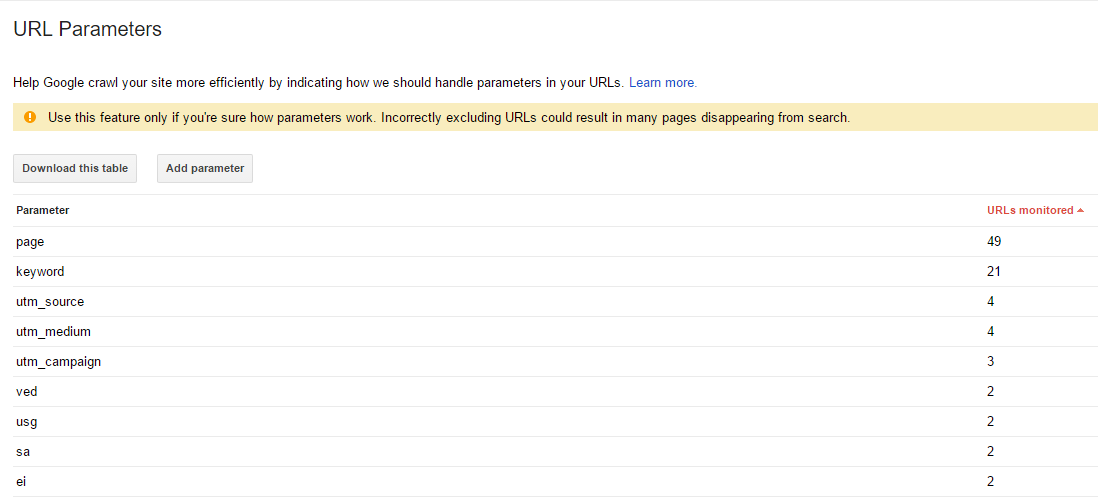
The information in this table has been automatically generated by Google, it contains the custom parameters that appear regularly in your URLs. Here you can edit the suggestions and add in new parameters to ensure you don’t have duplicate pages being indexed.
One thing to remember – using URL parameter tools indicate to search engines which pages to crawl/not crawl, so use this with caution, or seek help from an SEO expert.
8. Use feeds to your advantage
According to Google “Feeds are a way for websites large and small to distribute their content well beyond just visitors using browsers. Feeds permit subscription to regular updates, delivered automatically via a web portal, news reader, or in some cases good old email” .
Types of feed include RSS, XML and Atom. For example, if you are in the digital marketing industry and want to have a single feed of the latest posts from Search Engine Journal, Search Engine Watch and Moz – you can create a feed that collates all these publications.
Feeds are useful for web crawlers as they are among the most visited websites by search engine bots, as soon as you publish new content (products, services, blogs etc.) you can submit it to a feed burner to give search engines the heads up about fresh content and tell them that you want it indexing!
9 & 10. Identify low traffic pages & enrich your site with internal linking
Internal linking is a fantastic SEO technique, connecting one page of your website to another can:
- Improve your navigation
- Increase user engagement
- Distributes page authority
Take Wikipedia for example:
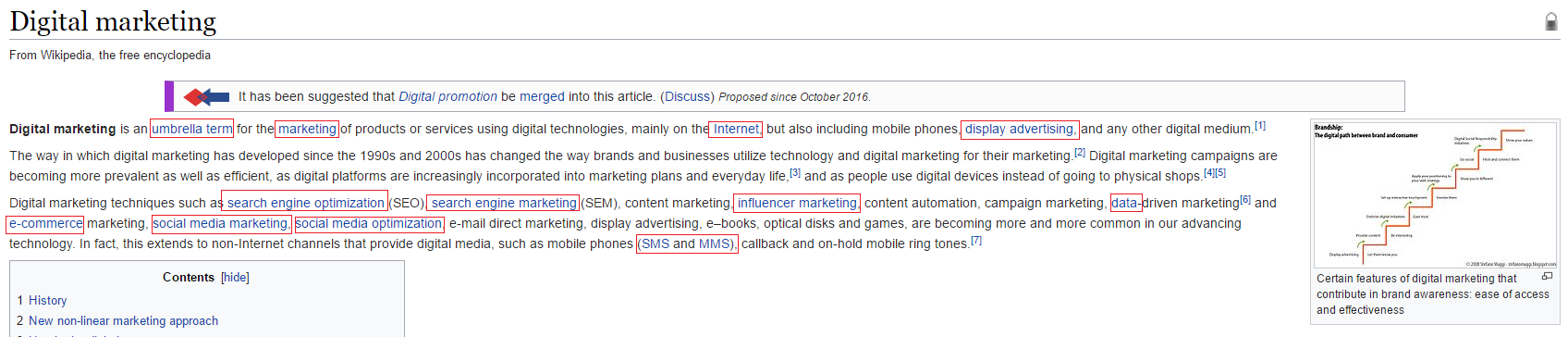
Have you ever looked up a topic on Wikipedia, clicked on a few internal links and before you know it ended somewhere completely different? This practice can be applied to any website, adding internal links can help a user flow through the content and the same applies to crawlers – these internal links provide pathways for spiders to browse your website.
Internal linking in general is great, however there are still a couple things to consider:
- Identify your low traffic pages: look for pages with low traffic over the past 12 months and identify where they are being linked to internally. If the content quality is low, then there really isn’t much point linking to it. Remove the links temporarily until you have updated the content. Once you start seeing more traffic, in about six to 12 months, you can then link to them.
- Give priority to your top pages: these are the pages with your best quality content, highest engagement rates etc. Identify pages that are creating revenue for your business and link to these more than other pages, so crawlers can see top pages more frequently. By linking more to high quality pages and passing more link juice to these pages, you will see that they typically start to rank higher and crawlers will index these pages more frequently.
- Don’t spread your internal links too thin: ideally you want users and crawlers alike to find all of your web pages. However, for the purpose of search engines it is more valuable to link to your high traffic pages that contain your best content. As long as you identify the reasons why the low traffic pages are under performing and improve these you can gradually bring these links back into the site.
If you have a very large website (1000+ pages) it is unlikely that every single page will drive large amounts of traffic. Nevertheless, these pages are useful to your users. In this situation, you could link to these pages internally and tell search engine crawlers to ignore them. For example, if you have pages with thin content (e.g. less than 100 words) that offer value to your users but not to search engines, you can block these pages off from search engine crawlers. What you will find is that search engine crawlers head to your more detailed pages with high content, which can lead to an increase in visibility.
For more information, refer to this awesome post on how internal links can improve your SEO.
11. Focus on building external links
Link building is, and for the foreseeable future will be, at the core of Search Engine Optimisation. SEO evangelist Paddy Moogan defined link building as:
“The process of acquiring hyperlinks from other websites to your own.” (Moz)
Yauhen Khutarniuk (Link Assistant) conducted a study to find out if there is correlation between the number of external links on a website and the number of visits received by search engine spiders. From analysing 11 sites and measuring Gooblebot hits, Internal Links and External Links a strong correlation was found between the number times a search engine spider visits a website and the number of external links. In addition to this, the study showed that the correlation between internal links and the number of times a spider visits a website is weak. Clearly identifying external backlinks an important factor in getting search engine bots to crawl your website.
There are several techniques for link building. For the sake of this post I will avoid going into too much detail about these but here are 5 tips to get started with Link building.
12. Improve your server speed
The faster your server is at responding to a page request, the more pages search engines are going to crawl. Don’t skimp on your hosting, you may be restricting the speed and number of pages being crawled. As a bot crawls each page of your website it will exert a certain amount of strain on your server, the more pages you have – the greater the strain. This will limit the number of pages that will be indexed.
One of the main reasons search engines crawl websites slowly is due to the website itself. However, if you notice your server load times are being directly affected by Googlebot you can change the crawl rate within the search console. To access this, head to Site Settings > Crawl Rate and choose ‘Limit Google’s maximum crawl rate’ as follows:
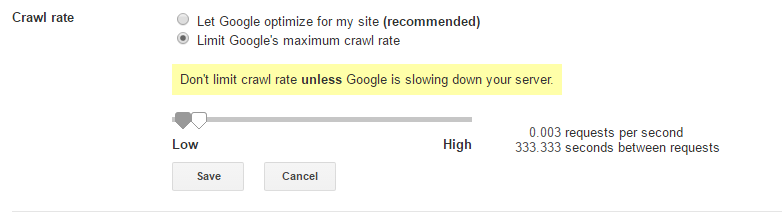
From here you can increase/decrease the rate at which Google crawls your site, if Googlebot is slowing down your server. This tool should be used with caution and we highly recommend matching your server to your goals, as oppose to altering the crawl rate with a below average server.
13. Optimise your page load speed
To check your page speed head over to Pagespeed Insights, this will identify the speed of a number of elements on your website across multiple devices. Not only is this handy for optimising your user experience, it also helps benchmark slow/fast loading pages to help optimise your crawl budget. The impact of page speed can be seen in this study from Sean Work (Kissmetrics) which shows the correlation between page load and abandonment:

We can see that for every second of page load the abandonment increasse at an exponential rate. Now think about this graph in terms of search engine crawlers – the longer the page takes to load, the longer it is going to take for a crawler to index your site, which will exhaust your crawl budget and potentially cause important pages not to be indexed.
14. Avoid AMP until you are in control
Accelerated Mobile Pages (AMP) which are designed to make extra fast mobile pages for users, have been the hot digital marketing topic for the past year. These pages are essentially a stripped down form of HTML that you can show instead of the regular version of your page. AMPs are by no means a substitute for responsive design – they are an addition.
The reasons AMP is included in this post is because you will be creating two versions of every web page, which in turn will double your crawl budget. AMP works by creating a separate URL for each page, for example, you would have: mysite.com/stuff/ and mysite.com/stuff/amp/. Here is an example:
Implementing AMP will double the work for search engine spiders. So, before jumping into using AMPs, ensure you have solved all of your crawl budget issues and are confident that by adding these pages you will not be creating more work.
15. Take control
Optimising your crawl budget should be an ongoing process that extends further than just heading into Google Search Console and submitting your/your clients site for indexing. Take time to work out your crawl budget and understand how this figure compares to the goals of your website. There are a number of techniques which can help optimise your crawl budget and although they take time and require care and attention – they will ultimately be worth the effort.
Too Long; Didn’t Read?
Crawl budget is the number of times a search engine crawls your website over a specific period of time. This number varies from one website to the next and has a direct effect on the number of pages that will be indexed. There are several ways you can optimise your crawl budget to increase the number of crawls you receive and enjoy faster updates when you create new content. The 15 tips mentioned in this post are:
1. Setting up Google Search Console and Bing Webmaster Tools
2. Making sure your pages are crawlable
3. Using a robots.txt file
4. Reducing redirect chains
5. Cleaning up broken links
6. Auditing and updating your sitemap
7. Telling search engines how to handle custom parameters
8. Using feeds to you advantage
9 & 10. Identifying low traffic pages and enriching your site with internal links
11. Building external links
12. Improving server speed
13. Optimising your page load speed
14. Avoiding AMP (for the time being)
15. Taking Control!
Optimising crawl budget requires a fairly high level of technical knowledge, the bigger the site, the more important it becomes and with the tips mentioned above you will be able to get off to a flying start. If you find yourself drowning in a sea of server logs and page speed tests, we have technical experts on hand to make it a breeze.
Have you found this article useful?
Get Team Hallam's expert advice and guidance straight to your inbox once a week.

